9
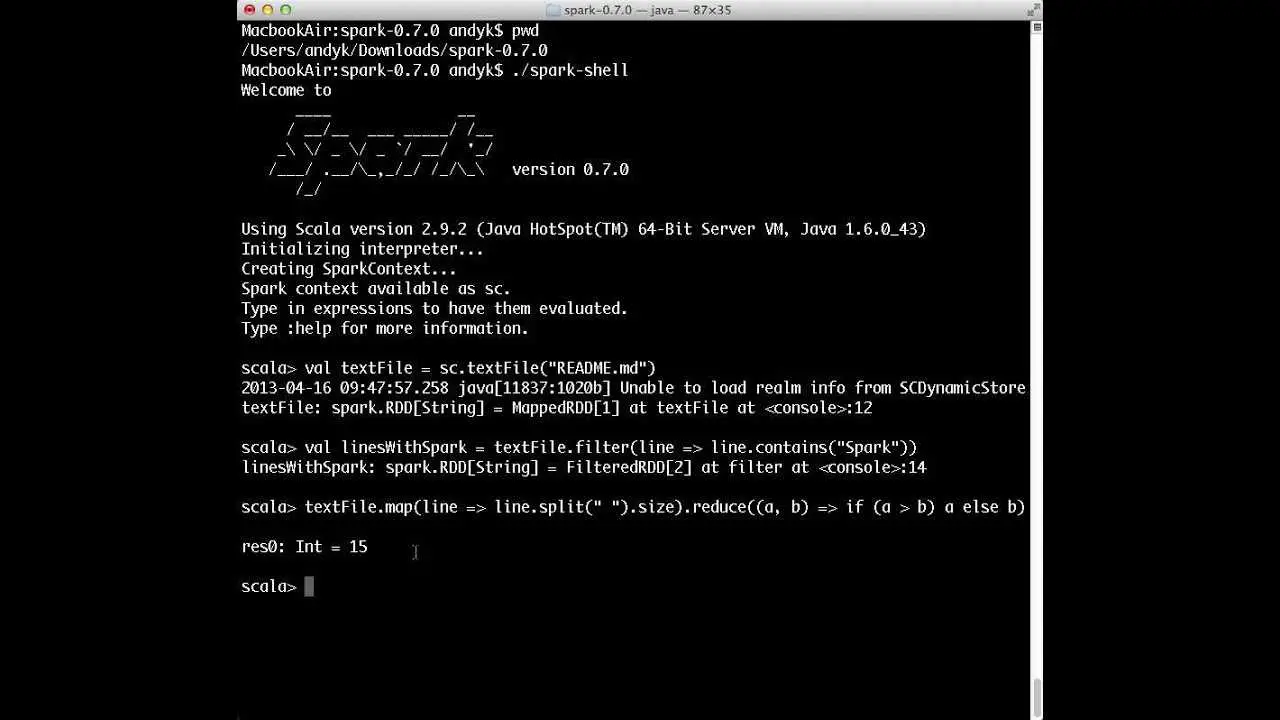
Apache Spark ™ to szybki i ogólny silnik do przetwarzania danych na dużą skalę.Szybkość Uruchamiaj programy do 100 razy szybciej niż Hadoop MapReduce w pamięci lub 10 razy szybciej na dysku.Spark ma zaawansowany mechanizm wykonywania DAG, który obsługuje cykliczny przepływ danych i przetwarzanie w pamięci.
Stronie internetowej:
http://spark.apache.orgKategorie