12
ArchiveBox
Self Samoobsługowe archiwum internetowe typu open source.Pobiera historię przeglądarki / zakładek / Pocket / Pinboard / itp., Zapisuje HTML, JS, pliki PDF, multimedia i więcej.
- Darmowa
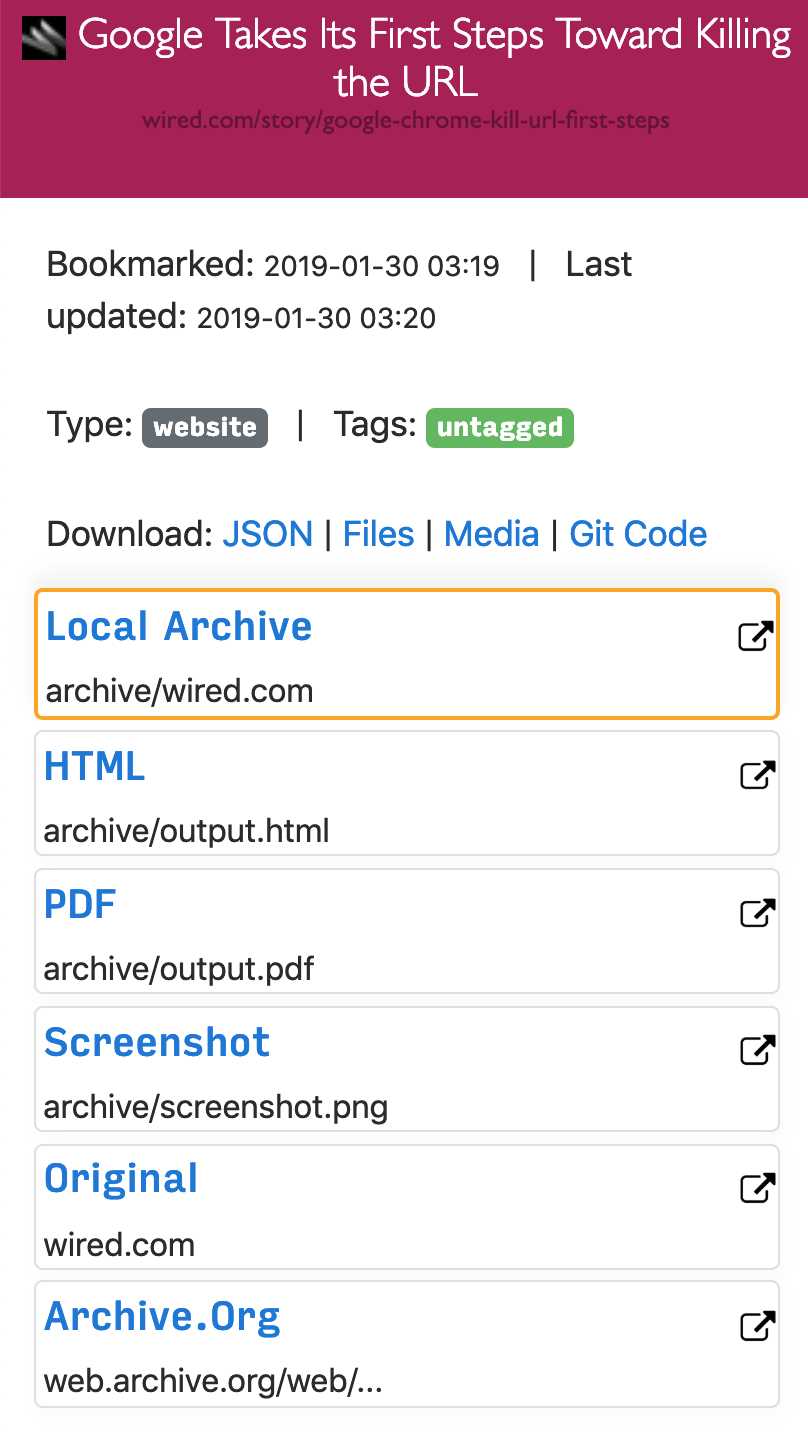
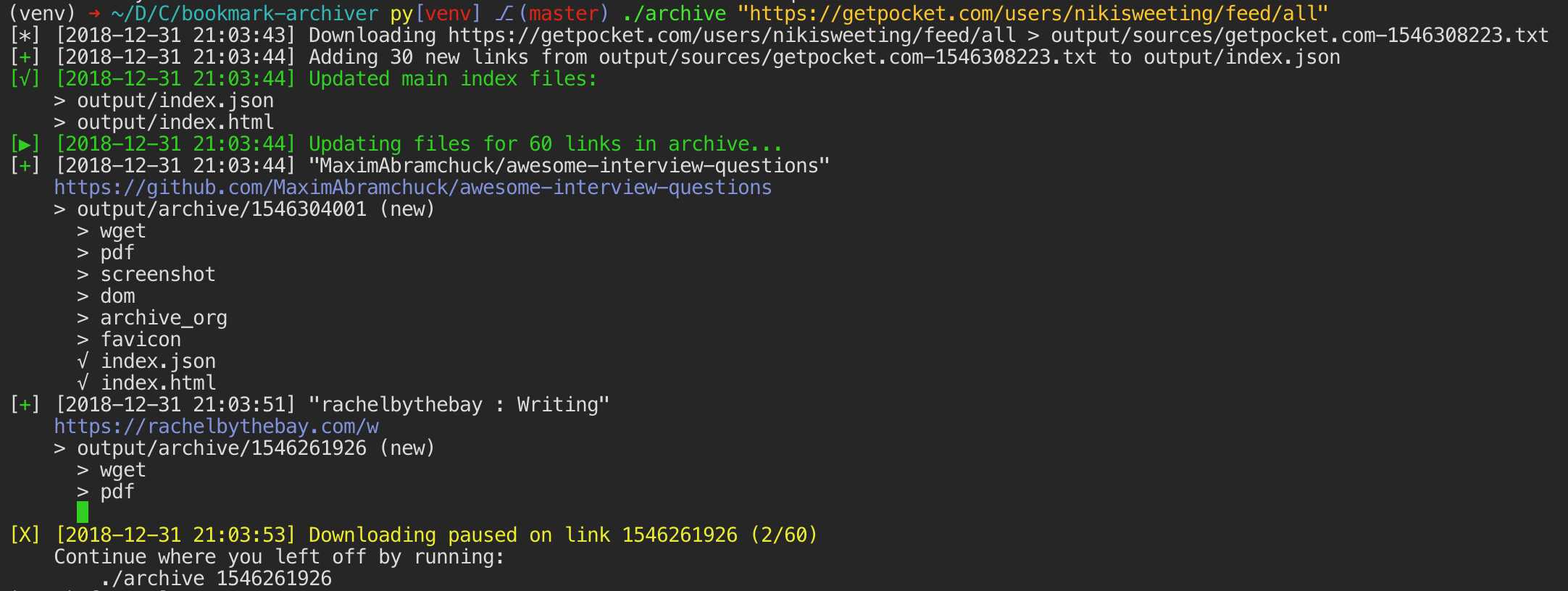
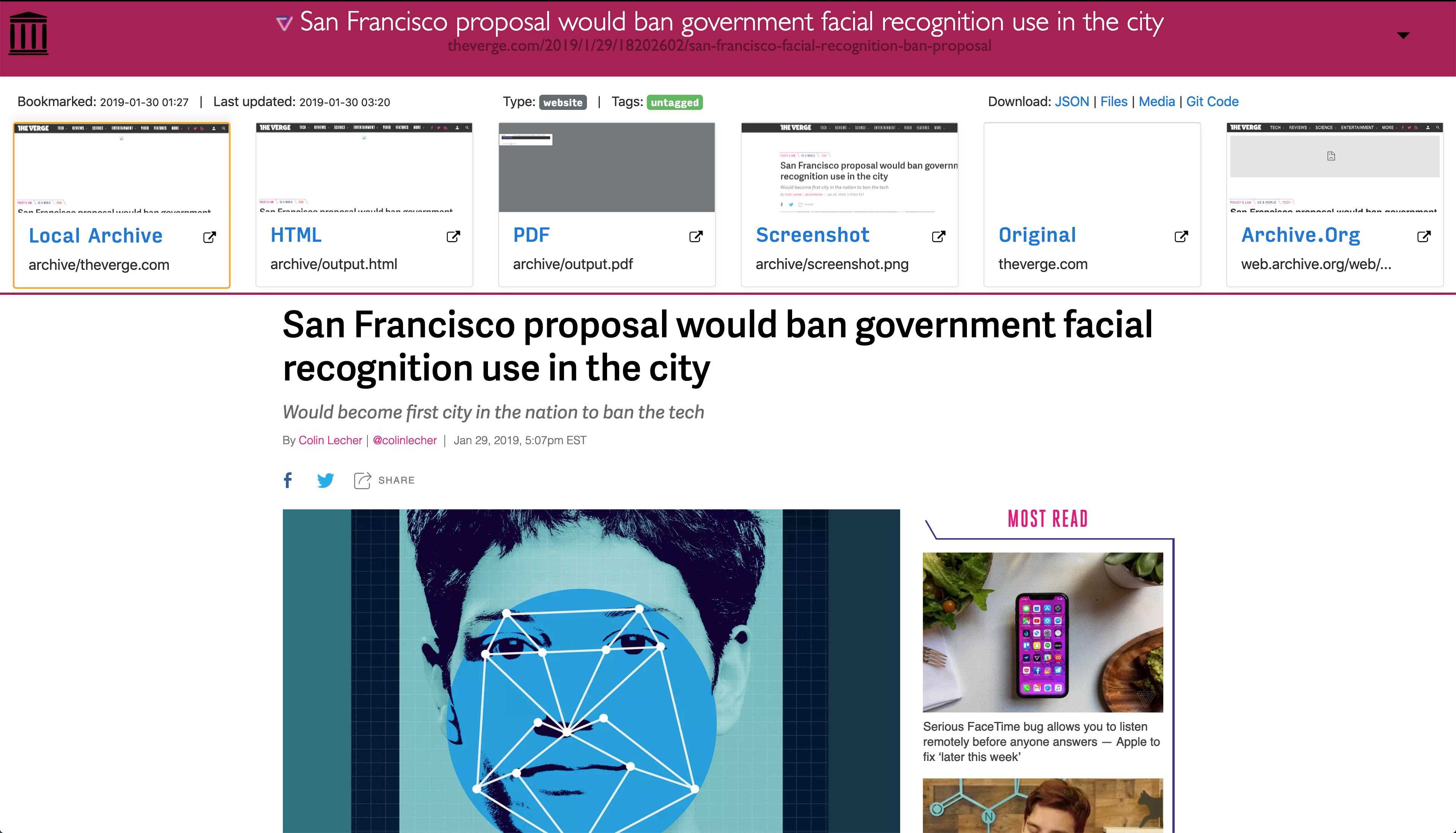
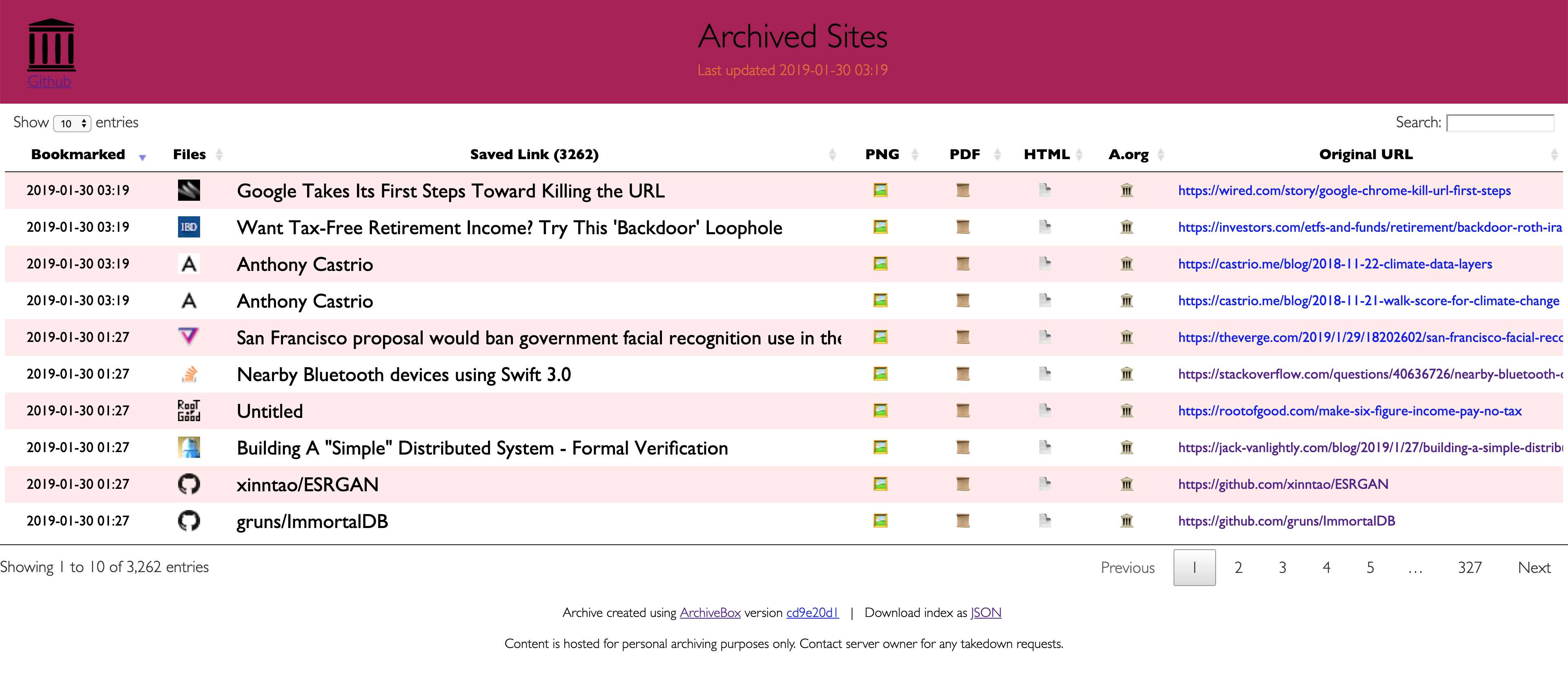
Ponieważ współczesne strony internetowe są skomplikowane i często opierają się na treści dynamicznej, ArchiveBox archiwizuje strony w kilku różnych formatach wykraczających poza to, co są w stanie zapisać publiczne usługi archiwizacji, takie jak Archive.org i Archive.is.ArchiveBox importuje listę adresów URL ze standardowego, zdalnego adresu URL lub pliku, a następnie dodaje strony do lokalnego folderu archiwum za pomocą wget, aby utworzyć możliwy do przeglądania klon html, youtube-dl do wyodrębnienia multimediów oraz pełną instancję przeglądarki Chrome bez pliku PDF,Zrzuty ekranu, zrzuty DOM i wiele innych ... Używanie wielu metod i dominującej na rynku przeglądarki do wykonywania JS gwarantuje, że możemy zapisać nawet najbardziej skomplikowane, wybredne strony internetowe w co najmniej kilku wysokiej jakości, długoterminowych formatach danych.### Może importować linki z: - Pocket, Pinboard, Instapaper - RSS, XML, JSON lub list zwykłego tekstu - Historia przeglądarki lub zakładek (Chrome, Firefox, Safari, IE, Opera i więcej) - Shaarli, Delicious, RedditZapisane posty, Wallabag, Unmark.it i każdy inny tekst z linkami!### Można zapisać te rzeczy dla każdej witryny: - favicon.ico` favicon witryny - `example.com / page-name.html` wget klon strony, z dołączonym .html, jeśli nie jest obecny - wyjście.pdf` Wydrukowano plik PDF strony przy użyciu bezgłowego chromu - `screenshot.png` 1440x900 zrzut ekranu strony przy użyciu bezgłowego chromu -` output.html` DOM Zrzut HTML po renderowaniu przy użyciu bezgłowego chromu - `archive.org.txt` Link do stronystrona zapisana na archive.org - `warc /` dla pliku html + gzipped warc.gz - `media /` any mp4, mp3, napisy i metadane znalezione przy użyciu youtube-dl - `git /` klon dowolnego repozytorium dla github, bitbucket lub gitlab links - `index.html` i` index.json`Pliki indeksu HTML i JSON zawierające metadane i szczegóły Archiwizacja jest addytywna, więc możesz zaplanować regularne uruchamianie `. / Archive` i pobieranie nowych linków do indeksu.Cała zapisana zawartość jest statyczna i indeksowana za pomocą plików JSON, dzięki czemu żyje wiecznie i jest łatwa do analizy, nie wymaga zawsze działającego backendu.
Kategorie
Alternatywy dla ArchiveBox'a dla wszystkich platform z dowolną licencją
2
WebArchives
Przeglądarka archiwów internetowych oferująca możliwość przeglądania w trybie offline milionów artykułów z dużych projektów społecznościowych, takich jak Wikipedia lub Wikisource.
1
Web Dumper
Pobierz całe witryny internetowe z Internetu i zapisz je na dysku twardym ...