0
OCR Text Detection Tool
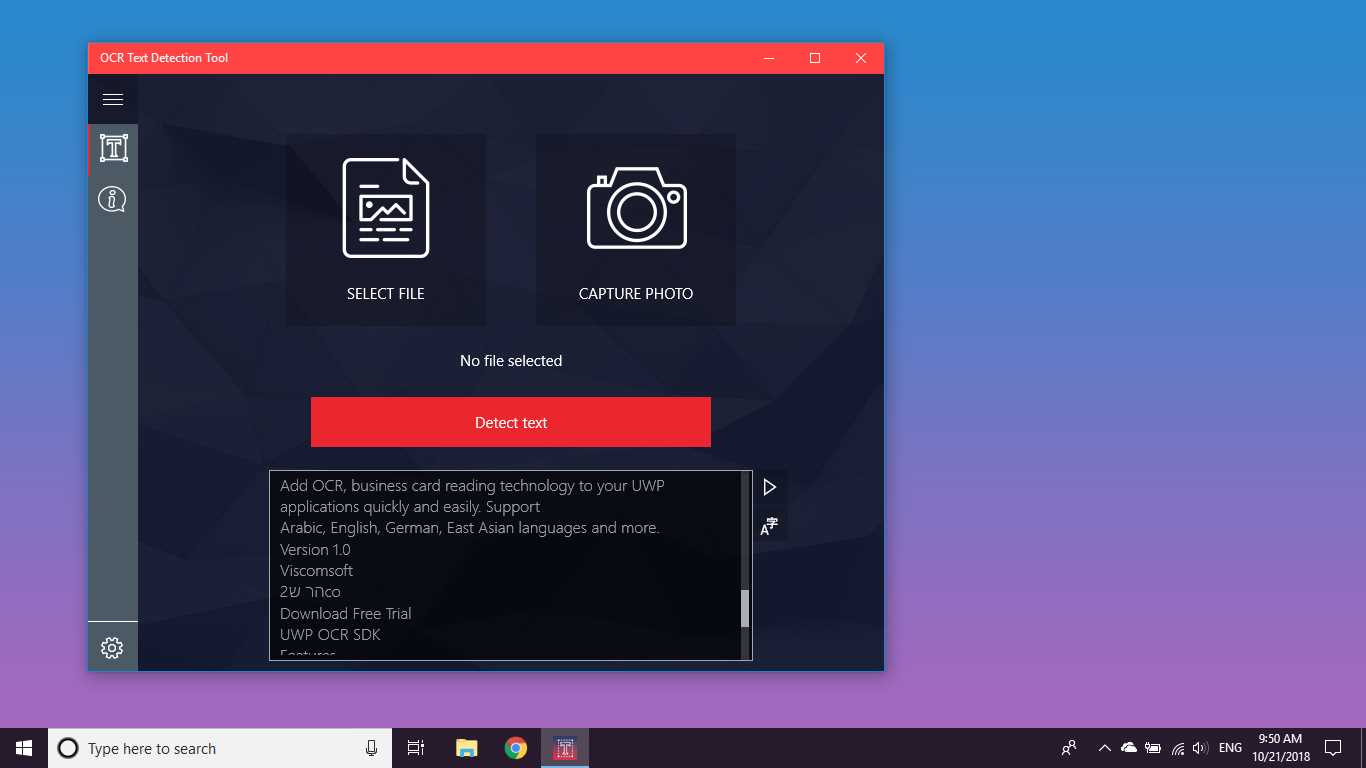
Zapewnia dokładne i szybkie wykrywanie tekstu z dowolnego pliku obrazu pobranego z urządzenia lub zrobionego z migawką.Obsługuje również wykrywanie tekstu w formacie PDF oraz wykrywanie pisma ręcznego na podstawie tekstu i tłumaczenie tekstu w 114 różnych językach.
- Darmowa
- Windows S
- Windows
- Windows Mobile
- Windows Phone
Narzędzie wykrywania tekstu OCR zapewnia dokładne i szybkie wykrywanie tekstu z dowolnego pliku obrazu pobranego z urządzenia lub zrobionego z migawką.Obsługuje również wykrywanie tekstowe dokumentu PDF (obecnie nie więcej niż 20 stron, ale pracujemy nad rozszerzeniem funkcjonalności).Aplikacja obsługuje również wykrywanie pisma ręcznego na podstawie tekstu i tłumaczenie tekstu na 114 różnych języków.Przyjazna, przejrzysta i wygodna konstrukcja sprawia, że praca z aplikacją jest łatwa i zrozumiała.* Dostępne formaty: JPEG, PNG8, PNG24, GIF, animowany GIF (tylko pierwsza klatka), BMP, WEBP, RAW, ICO, TIFF, PDF (obecnie nie więcej niż 20 stron, ale pracujemy nad rozszerzeniem funkcjonalności) * Tekstfunkcja rozpoznawania jest w stanie wykryć wiele różnych języków i może wykryć wiele języków na jednym obrazie: afrykanerski (af), arabski (ar), asamski (as), azerbejdżański (az), białoruski (be), bengalski (bn), Bułgarski (bg), kataloński (ca), chiński (zh *), chorwacki (hr), czeski (cs), duński (da), holenderski (nl), angielski (en), estoński (et), filipiński (fillub tl), fiński (fi), francuski (fr), niemiecki (de), grecki (el), hebrajski (he lub iw), hindi (hi), węgierski (hu), islandzki (is), indonezyjski (id), Włoski (it), japoński (ja), kazachski (kk), koreański (ko), kirgiski (ky), łotewski (lv), litewski (lt), macedoński (mk), marathi (mr), mongolski (mn), Nepalski (ne), norweski (no), paszttu (ps), perski (fa), polski (pl), portugalski (pt), rumuński (ro), rosyjski (ru), sanskryt (sa), serbski (sr), Słowacki (sk), słoweński (sl), hiszpański (es), szwedzki (sv), tamilski (ta), tajski (th), turecki (tr), ukraiński (uk), urdu (ur), uzbecki (uz), wietnamski (vi) Sprawdź, nie masz nic do stracenia!
Stronie internetowej:
https://www.microsoft.com/store/apps/9PL1PPFPT8VJKategorie
Alternatywy dla OCR Text Detection Tool dla Linux
71
35
GImageReader
gImageReader to prosty interfejs Gtk / Qt do silnika Tesseract OCR. Funkcje: - Importuj dokumenty PDF i obrazy z dysku, urządzeń skanujących, schowka i zrzutów ekranu
9
8
6
5
5
4